
Отже, на комп'ютері в нас встановлено FineReader. Включаємо сканер і оцифровуємо якийсь багатосторінковий документ. Назвемо його, умовно, "Договір".
Укладаємо на скло сканера першу сторінку документа, закриваємо кришку. Запускаємо програму FineReader. Клацаємо кнопку "Сканувати", або клавішами тиснемо поєднання "Ctrl + K". Відкриється вікно "Сканування ABBYY FineReader". При оцифровці звичайної текстової сторінки, набраної шрифтом в 11-12 пунктів, залишаємо налаштування у вікні за замовчуванням і натискаємо кнопку "Перегляд".
Сканер працює і через кілька секунд бачимо нашу сторінку у вікні перегляду. Тут ми можемо змінити розмір скана, якщо треба. І потім натискаємо кнопку "Сканувати".
FineReader починає процес розпізнавання тексту та протягом хвилини зображення сторінки відкривається у вікні програми. Права частина вікна ділиться тепер на три розділи. У лівому розділі "Зображення" ми можемо редагувати зображення. Докладніше про редагування зображення можна прочитати в уроці: Сканування книги . У правому розділі "Текст" можна відразу вносити зміни до тексту - редагувати зміст сторінки ще до збереження. Це дуже зручно, коли потрібно, наприклад, швидко змінити у документі дати, реквізити, прізвища.
У лівій частині вікна "Сторінки" з'являється піктограма розпізнаної сторінки:
Якщо редагувати нічого не потрібно, замінюємо першу сторінку на склі сканера на другу сторінку і повторюємо технологію. Один раз налаштувавши розміри скана у вікні "Сканування ABBYY FineReader" у режимі "Перегляд" для першої сторінки, тепер одразу натискаємо кнопку "Сканувати". Встановлені для першої сторінки установки зберігаються, і наступні сторінки скануємо без попереднього перегляду. Так скануємо усі сторінки нашого документа.
Закінчили, і тепер, по черзі клацаючи по піктограмах, відкриваємо сторінки, перевіряючи правильну їх послідовність.
Після цього у лівій частині вікна "Сторінки" виділяємо всі піктограми кнопкою: "Правка - Виділити все" або клавіатурним поєднанням: "Ctrl+A". Потім, у списку, що випадає, поруч з кнопкою "Зберегти" вибираємо команду: "Зберегти як документ PDF":

Плескаємо тепер за самою кнопкою і зберігаємо документ з ім'ям "Договір.pdf" у папку "Договір":

У результаті отримуємо багатосторінковий текстовий документ pdf-формату – електронну версію нашого документа з умовною назвою "Договір".
Так, FineReader'ом оцифровуємо текстові документи.
Змінивши режим сканування на кольоровий у вікні Сканування ABBYY FineReader також легко оцифруємо кольорові картинки і фотографії.
А, поставивши в контекстному меню, наприклад, команду: "Зберегти як документ Microsoft Word 2007" перетворимо наш проект на єдиний багатосторінковий документ, що редагується.
Втім, програма легко засвоювана, інтуїтивно зрозуміла і скрізь підказки.
Abbyy Finereader – програма для розпізнавання тексту із зображеннями. Джерелом картинок, як правило, є сканер або МФУ. Прямо з вікна програми можна зробити сканування, після чого автоматично перевести зображення до тексту. Крім того, Файн Рідер вміє сконвертувати отримані зі сканера зображення у форматі PDF та FB2, що корисно при створенні електронних книг та документації для подальшого друку.
Як усунути проблему: ABBYY Finereader не бачить сканер.
Для коректної роботи Abbyy Finereader 14 (остання версія) на комп'ютері повинні виконуватись такі вимоги:
- процесор із частотою від 1 ГГц та підтримкою набору інструкцій SSE2;
- Windows 10, 8.1, 8, 7;
- оперативна пам'ять від 1 Гб, рекомендована – 4 Гб;
- TWAIN- або WIA-сумісний пристрій для введення зображень;
- доступ до Інтернету для активації.

Якщо ваше обладнання не відповідає цим вимогам, програма може працювати некоректно. Але й за дотримання всіх умов, Abbyy FineReader часто видає різні помилки сканування, такі як:
- неможливо відкрити джерело TWAIN;
- параметр заданий неправильно;
- внутрішня програмна помилка;
- помилка ініціалізації джерела.
У переважній більшості випадків проблема пов'язана із самим додатком та його налаштуваннями. Але іноді помилки виникають після оновлення системи або після підключення нового обладнання. Розглянемо найпоширеніші рекомендації, що робити, якщо ABBYY FineReader не бачить сканер та видає повідомлення про помилки.
Виправлення помилок
Є низка загальних порад щодо виправлення некоректної роботи:
- Оновіть драйвери обладнання до останніх версій із офіційного сайту виробника.
- Перевірте права поточного користувача в системі, за потреби підвищуйте рівень доступу.
- Іноді допомагає встановлення більш старої версії програми, особливо якщо ви працюєте на новому обладнанні.
- Перевірте, чи бачить сканер сама система. Якщо він не відображається в диспетчері пристроїв або показаний з жовтим знаком оклику, то проблема в обладнанні, а не програмі. Зверніться до інструкції або технічної підтримки виробника.
- На офіційному сайті ABBYY працює непогана технічна підтримка https://www.abbyy.com/ru-ru/support. Ви можете поставити питання, детально описавши саме свою проблему, і отримати професійне рішення з перших рук абсолютно безкоштовно.

Усунення помилки «Параметр неправильний»
В останній версії ABBYY FineReader також може називатися "Помилка ініціалізації джерела". Ініціалізація – це процес підключення та розпізнавання системою обладнання. 
Якщо Файн Рідер не бачить сканер під час запуску діалогового вікна сканування та видає такі помилки, то повинні допомогти наступні дії:
- Перезапустіть програму FineReader.
- Зайдіть в меню "Інструменти", виберіть "OCR-редактор".
- Натисніть "Інструменти", потім "Налаштування".
- Увімкніть «Основні».
- Перейдіть до «Вибір пристрою для отримання зображень», а потім виберіть «Виберіть пристрій».
- Натисніть на список доступних драйверів. Перевірте, чи є сканування по черзі з кожним зі списку. У разі успіху з одним із них, використовуйте його надалі.

УВАГА. Можлива й така ситуація, що ні з яким доступним драйвером виконати сканування не вдалося. Натисніть «Використовувати інтерфейс сканера».
Якщо це не допомогло, вам знадобиться утиліта TWAIN_32 Twacker. Її можна завантажити з офіційного сайту ABBYY на посилання ftp://ftp.abbyy.com/TechSupport/twack_32.zip.
Після цього дотримуйтесь інструкцій:
- Вийдіть із Файн Рідер.
- Розпакуйте архів twack_32.zip у будь-яку папку.
- Двічі клацніть на Twack_32.exe.
- Після запуску програми зайдіть в меню "File", потім "Acquire".
- Натисніть «Scan» у діалозі, що відкрився.
- Якщо документ успішно відсканувався, відкрийте меню "File" і клацніть "Select Source".
- Синім кольором виявиться відображений драйвер, через який утиліта успішно виконала сканування.
- Виберіть цей файл драйвера у файнрідері.

Якщо при запуску в Abbyy Finereader цього зробити знову не вдалося, значить проблема в роботі програми. Надішліть запит на технічну підтримку ABBYY. Якщо ж і 32 Twacker не зміг виконати команду Scan, то, ймовірно, некоректно працює сам пристрій або його драйвер. Зверніться до технічної підтримки виробника сканера.
Внутрішня програмна помилка
Буває, що при запуску сканування програма повідомляє «Внутрішня програмна помилка, код 142». Вона зазвичай пов'язана з видаленням або пошкодженням системних файлів програми. Для виправлення та запобігання повторним появам виконайте таке:

Іноді Файнрідер може не бачити сканер через обмеження доступу. Запустіть програму від імені адміністратора або збільште права поточного користувача.
У такий спосіб вирішується проблема підключення програми Fine Reader до сканера. Іноді причина конфлікту драйверів або несумісності обладнання. А буває, збій сканування виникає через внутрішні програмні помилки. Якщо ви стикалися з подібними проблемами у файнрідері, залишайте поради та способи вирішення у коментарях.
Робота з розпізнавання зображень складається з наступних етапів:
- Отримати відскановані зображення (скани).
- Відкрити їх у OCR-програмі (FineReader).
- Зробити розмітку сторінок на блоки. Тобто, розбити сторінку на області, в кожній з яких буде або текст, або малюнки, або таблиці, або інший однорідний вміст.
- Власне розпізнавання.
- Вичитування розпізнаного, звіряння отриманого тексту та вихідних сканів.
- Збереження отриманих результатів в одному з документальних форматів (DOC, RTF, PDF, HTML тощо).
При розпізнаванні текстів можливі два варіанти: або ви скануєте матеріал самі, або працюєте з відсканованим текстом.
У першому випадку етапи "Отримати зображення" та "Відкрити зображення" об'єднуються в одне - FineReader отримані скани відразу ж відкриває у своєму пакеті. У другому випадку етап «Отримати зображення» вже пройдено, треба лише відкрити їх у програмі.
Розглянемо обидва варіанти по черзі.
Відсканувати текст у FineReader
Сканування запускається через "Файл → Сканувати сторінки" або кнопкою меню "Сканувати", або Ctrl-K.
Мал. 1 Інтерфейс сканування
Однак, перш ніж починати сканувати, непогано було б розібратися, як отримати скани, найбільш оптимальні для розпізнавання. А для цього зрозуміти, чим хороший (з точки зору FineReader) скан відрізняється від не дуже хорошого.
Для якісного розпізнавання програмі потрібні три речі. По-перше, можливість надійно відрізнити текст та ілюстрації від фону сторінки. По-друге, щоб літери, цифри та інший вміст були чіткими та розбірливими, щоб не виникало ситуацій «тут і людське око не завжди зрозуміє, що саме надруковано». По-третє, рядки тексту на скані повинні йти так само, як вони надруковані на сторінці книги, без перекосів і спотворень. Є ще інші вимоги до якісного скану, але ці можна вважати ключовими.
1. Для надійного розрізнення "тут текст, а тут фон сторінки" потрібно, щоб перехід між тим і іншим був різким, не розмитим. Ось зразки сторінок із поганою та з хорошою чіткістю. У першому випадку, природно, розпізнаватиметься гірше, з великою кількістю помилок.

Мал. 2. Розмиті межі літер

Мал. 3. Точні межі літер
Звичайна причина розмитих кордонів "текст-фон" - сканування з порушеним фокусуванням, те, що зазвичай називають "не у фокусі". Тому перед початком роботи бажано перевірити сканер на цей момент.
Інша причина, яка може завадити розрізненню тексту та фону – надто «щільний» фон сторінки. У нормі він повинен бути або чисто білим, або білим з невеликою домішкою якогось кольору. Якщо скануються книги старих видань, де папір часто буває пожовклим, то фон може бути жовтуватий (але помірно).
Якщо ж фон виглядає помітно перетемненим, то такі сторінки знову ж таки будуть розпізнаватись гірше.
Те, який вигляд буде біля фону, залежить від яскравості сканування. Її можна регулювати через двигун «Яскравість». Для початку має сенс поставити 50%, перевірити, що при цьому буде, за потреби виправити.
2. Розбірливість літер тексту в основному залежить від яскравості та від роздільної здатності сканування.
Якщо яскравість занадто велика, лінії літер будуть рваними, вони будуть розсипатися на окремі шматочки. Якщо яскравість мала, деталі літер починають зливатися між собою, виникають безформні плями. І те, й інше для програм розпізнавання не дуже їстівна «їжа».
Яскравість тут налаштовується так, як і в попередньому випадку - ставимо для початку в інтерфейсі сканування 50%, а далі за ситуацією.

Мал. 4. Сторінка із занадто великою яскравістю

Мал. 5. Сторінка із надто маленькою яскравістю (перетемнений фон сторінки)

Мал. 6. А ось ця ж сторінка, але в нормальному вигляді
Дозвіл сканування визначає скільки пікселів у скані припадатиме на кожну букву. Якщо цих пікселів достатньо для відтворення контуру літери, то проблем при розпізнаванні не буде. Якщо ж недостатньо, то літери можуть стати погано помітними навіть для людського ока, а про програми розпізнавання.

Мал. 8. Те саме, але на 200 точок

Мал. 9. Те саме, але на 400 точок
При виборі дозволу зазвичай керуються такими правилами:
- 300 пікселів вибирається для книг масових видань (сторінки заповнені текстом звичайного розміру, майже без малюнків);
- 400 точок вибирається для книг та журналів з помітним обсягом тексту невеликими кеглями (примітки, підписи під малюнками, таблиці, врізання дрібним текстом);
- 600 точок вибирається для книг, надрукованих зовсім дрібними кеглями (багато довідників та енциклопедій, книг-мініатюр). Або ж із дрібнодеталізованими малюнками, наприклад, гравюрами. Сюди треба віднести багато книг видання 1990-х років - тоді видавці економили на папері і часто друкували зовсім крихітними літерами.
Інтерфейс сканування в FineReader дозволяє вибирати лише 300 пікселів або 600 (рядок «Дозвол»). Тому якщо у вас багато матеріалу, який бажано робити на 400 точок, то краще сканувати не з FineReader, а з програми, що йде разом зі сканером.
Або в налаштуваннях FineReader переключитися з власного інтерфейсу програми на TWAIN-інтерфейс вашого сканера («Сервіс → Установки → закладка «Сканувати/Відкрити» → клацнути внизу по «Використовувати інтерфейс сканера»). Тоді ви зможете сканувати з FineReader, але працюватимете в інтерфейсі сканера (зазвичай там більший обсяг налаштувань та функцій).
3. Рівні, акуратно виглядають рядки тексту переважно забезпечуються передобробкою зображення («перед-» у разі означає «виконуване після сканування, але перед розпізнаванням»). Після правильно зробленої попередньої обробки вміст сторінок розпізнаватиметься з вищою якістю.
FineReader має досить багатий набір функцій, який можна побачити в налаштуваннях програми, на закладці «Сканувати/Відкрити». Також це віконце можна викликати через кнопку «Налаштування» у вікні інтерфейсу сканування.

Мал. 10. Налаштування попередньої обробки
"Ділити розворот книги" треба вибирати, коли книга сканувалася не посторінково, а розворотами. Тоді для розпізнавання вони будуть нарізані посторінково.
"Визначити орієнтацію сторінок" використовується в тому випадку, якщо книга сканувалася поверненою набік. Тоді вона буде розгорнута у своє нормальне становище. Але якщо у книзі є сторінки, які надруковані повернутими на 90 градусів щодо основної маси, то галочку тут краще зняти. Інакше при виведенні розпізнаного у PDF ви можете отримати частину сторінок у «книжковій» орієнтації, а частина – у «альбомній». Повернути потрібні сторінки в цьому випадку краще вручну, у вбудованому редакторі зображень
"Виправити перекоси" усуває перекоси сторінок. Налаштування однозначно необхідне, але треба мати на увазі, що PDF «Текст під зображенням сторінки», отриманий з таких сканів, матиме не зовсім акуратний вигляд - сіруваті клини по краях сторінки (там де робився поворот).
"Виправити спотворення рядків" вирівнює вигини рядків, які при скануванні часто утворюються біля палітурки (їх ще називають "вуси").

Мал. 11. Приклад сторінки з вигинами рядків
"Усунути трапецієподібні спотворення" виправляє деформації сторінок, що з'являються, якщо книга не дуже щільно притиснута до скла сканера.
«Інвертувати зображення» необхідна, якщо в матеріалі, що сканується, багато тексту «світлі літери на темному тлі» і ви хочете перетворити їх у звичайне «темні літери на світлому фоні».
"Видалити кольорові елементи" корисно, якщо на сторінці виду "чорні літери на білому тлі" треба прибрати різні непотрібності, на кшталт позначок ручкою на полях, підписів та печаток (офісна документація), а то й просто плям. Але якщо на цій же сторінці є якісь зроблені в кольорі "потрібності" - графіки, діаграми чи фотографії, то галочку ставити не можна. Інакше буде видалено і вони.
"Виправити роздільну здатність зображень" - пункт, який вимагає більш розгорнутого пояснення, ніж попередні. Справа в тому, що процес розпізнавання у FineReader дуже чутливий до того, яке дозвіл виставлено у властивостях цього зображення. Від цього суттєво залежить те, наскільки точно будуть визначені кеглі букв тексту, міжлітерні та міжрядкові відстані та інше. Тому галочка тут потрібна. Крім того, не варто дивуватися, якщо по ходу розпізнавання ви постійно отримуватимете повідомлення FineReader «на сторінці такий-то неправильно виставлено дозвіл і добре б його виправити».
Крім налаштувань попередньої обробки на закладці «Сканувати/Відкрити» є блок налаштувань «Загальне». Тут задається набір основних дій, які будуть виконані над сторінками, що відкриваються. Варіанти таких дій можуть бути такі:
- просто відкрити відскановані зображення, нічого з ними при цьому не роблячи. Для цього треба зняти галочку "Автоматично обробляти додані сторінки".
Подібне має сенс тільки в тому випадку, якщо у вас скани настільки високої якості, що їх нічим особливо не поліпшиш. Можна одразу відправляти на розпізнавання. Буває звичайно і таке, але набагато рідше, ніж хотілося б:-), тому галочку краще залишити. - відкрити зображення, виконати передобробку, але до вашої команди поки що нічого не робити. Для цього потрібно вибрати пункт «Переробка зображень».
Так зазвичай роблять якщо треба не запускати відразу розпізнавання, а спочатку подивитися, що вийшло в результаті попередньої обробки, наскільки вона добре відпрацювала за цим набором зображень. - відкрити зображення, виконати попередню обробку, виконати розмітку на блоки, розпізнавання поки що не запускати. Для цього треба вибрати пункт "Аналіз зображень (включаючи передопрацювання)".
Найбільш часто обирається варіант. Скани у вас цілком пристойної якості, те, що з ними зробить передобробка, ви добре уявляєте, перевіряти після неї немає необхідності. Отже з'єднуємо в одне три описані вище етапи роботи із зображеннями і починаємо дивитися наскільки добре зроблена розмітка. - всі етапи розпізнавання проходять автоматично, без будь-якого проміжного контролю. Ви одразу отримуєте готовий результат і починаєте його вичитувати. Для цього потрібно вибрати пункт "Розпізнавання зображень (включаючи передопрацювання)". Так має сенс робити тільки якщо у вас скани гарної якості та з дуже простим зовнішнім виглядом – наприклад суцільний текст однією мовою і нічого більше. В інших випадках краще вибирати варіант 2 або 3. Особливо якщо у вас сторінки зі складним форматуванням, таблицями, діаграмами, малюнками і т.д.

Мал. 12. Приклад сторінки зі складною версткою

Мал. 13. Приклад сторінки зі складною версткою
Відкрити зображення у FineReader
Це другий варіант роботи із зображеннями: не сканувати їх самому, а отримати в готовому вигляді і відкрити в FineReader. Робиться через кнопку "Відкрити" в меню основного вікна або через "Файл → Відкрити PDF або зображення", або через Ctrl-O.

Мал. 14. Вікно «Відкрити зображення»
У вікні Провідника, що відкрилося, вибираєте зображення, задаєте необхідні налаштування (кнопка «Налаштування») і натискаєте «Відкрити». Налаштування тут використовуються ті самі, що описані для сканування, працювати з ними треба так само.
Коли сторінки відкриті у FineReader, то пакет за замовчуванням створюється безіменним («Документ без імені») і зберігається в TMP-папці лише в межах поточного сеансу роботи. Щоб випадково не втратити результати роботи, рекомендується відразу після створення зберегти пакет під якимось постійним ім'ям («Файл → Зберегти документ FineReader»).
Розмітка сторінок на блоки
Після того, як ви відкрили скани, необхідно виконати розмітку сторінок на блоки. Це робиться через "Документ → Аналіз документа" або через Ctrl-Shift-E.
Основних робочих цілей у розмітки дві.
По-перше, відокремити те, що на сторінці є текст від того, що текстом не є. «Текстом» у разі вважається усе, що FineReader може розпізнати. "Не-текстом" відповідно вважається все, що він розпізнати не в змозі. В основному це ілюстративна частина сторінки - малюнки, креслення, графіки, діаграми та інше. Формули, рукописні записи та ноти з цієї точки зору теж вважаються нетекстом - розпізнавати їх FineReader поки не вміє. А отже, при розмітці їх треба помітити, як «картинка».
По-друге, ще треба те, що є текст, розмітити за категоріями – просто текст, таблиці, примітки (виноски), колонтитули, зміст тощо. Щоб потім, коли ви читатимете розпізнане в текстовому редакторі, всі ці елементи виглядали б саме так, як ви і звикли (були б відформатовані відповідним чином).
Розмічена сторінка може мати приблизно такий вигляд:

Мал. 15. Вікно «Зображення» із розміченою сторінкою
Тепер треба переглянути розмітку, зроблену програмою на кожній зі сторінок та за необхідності поправити її.
Похибки розмітки зазвичай бувають таких видів.
1. Якась частина вмісту сторінки (текст, малюнок і т.д.) виділена правильно в сенсі меж області, але їй присвоєно не той вміст. Наприклад, фрагмент тексту розмічений як малюнок або навпаки.
У цьому випадку треба клацнути мишею по такій області, відкрити контекстне меню, вибрати в ньому «Змінити тип області», у підменюшці, що відкрилася, вибрати необхідний тип («Текст», «Таблиця», «Картинка», «Фонова картинка», «Штрих- код»).

Мал. 16. Контекстне меню "Змінити тип області"
Швидко подивитися, де яка область можна за кольором рамок. "Текст" виділяється рамками темно-зеленого кольору, "Таблиця" - синього, "Картинка" - світло-червоного, "Фонова картинка" - темно-червоного, "Штрих-код" - світло-зеленого.
2. У змісті область виділено правильно, але у сенсі розмірів (меж) виділено в повному обсязі, що у разі потрібно. Або ж навпаки – потрапив шматок від сусідньої області з іншим вмістом.

Мал. 17. Сторінка з некоректно зробленою розміткою
До верхньої області «картинка» прихоплені навколишні підписи (мають бути розмічені, як «текст»).
У нижню область «картинка» під час розмітки не потрапила частина зображення.
Щоб це виправити, потрібно спочатку клацнути в віконці «Зображення» на кнопку «Стрілка».
А потім клацати по кожній неправильно розміченій області та переміщати її межі. Приблизно так само, як зазвичай переміщають межі вікон відкритих програм.
3. Якась частина вмісту сторінки розміткою взагалі пропущена, не потрапила до жодної із створених областей.

Мал. 18. З розмітки випала формула (не потрапила до жодного з блоків)
Тут потрібно буде створити на сторінці нову область (виділити пропущену частину сторінки рамкою), а потім присвоїти створеній області потрібний тип.
Для цього треба спочатку клацнути у віконці «Зображення» за значком «Виділити зону розпізнавання»
Після цього обвести потрібну ділянку рамкою (як зазвичай у графічному редакторі виділяють частину малюнка) і нарешті задати тип області. Остання операція описана в пункті 1.
Якщо текстова частина сторінки вам потрібна просто, як суцільний текст (що найчастіше і буває), цього цілком достатньо. Якщо ж ви хочете, щоб у Word різні елементи оформлення розпізнаних сторінок (примітки, колонтитули) виглядали б саме як примітки та колонтитули, то треба перевірити і цей момент.
Він регулюється через контекстне меню. Клацаєте по потрібній області «Текст» на сторінці, що перевіряється, в контекстному меню вибираєте пункт «Призначення тексту», всередині його підменюшки дивіться проти якого пункту стоїть галочка (зазвичай це «Автовизначення»). Якщо стоїть не там, де треба, перемикаєтесь на потрібний елемент.

Мал. 19. Контекстне меню "Призначення тексту"
Розпізнавання
Після виправлення помилок у розмітці можна запускати розпізнавання. Це робиться через "Документ → Розпізнати документ" або через Ctrl-Shift-R. Перед цим не забудьте виставити мову розпізнавання та встановити необхідні налаштування.
Мова виставляється через вікно «Мова документа» на панелі кнопок основного вікна програми.

Мал. 20. Вибір мови через головне меню
Або в установках («Сервіс → Установки → закладка «Документ»).

Мал. 21. Вибір мови через налаштування FineReader
Якщо в списку немає потрібної вам мови, то натисніть «Вибір мов» в нижній частині списку і у вікні, що відкрилося, поставте галочку проти необхідної вам мови (набору мов). Після цього його буде додано до списку.
У налаштуваннях розпізнавання («Сервіс → Установки → закладка «Розпізнати») режим розпізнавання краще залишити за замовчуванням («Ретельне розпізнавання»). "Швидке розпізнавання" має сенс ставити тільки якщо у вас щось нескладне на вигляд і з дуже гарною якістю сканування. Наприклад, відсканований у чорно-білому роздрук текстового документа без ілюстрацій.

Мал. 22. Налаштування, закладка «Розпізнати»
З решти налаштувань основне значення має група «Визначення структурних елементів». Тут перераховані деталі оформлення сторінок: виноски (примітки), колонтитули, списки, зміст. Коли проти елемента поставлена галочка, він буде розпізнаний та збережений у DOC/RTF/DOCX не просто як частина тексту на сторінці, а саме, як виноска, колонтитул, список чи зміст.
Тільки не забудьте важливий момент. Якщо вам доводиться розпізнавати області з подібним вмістом, то однієї галочки в налаштуваннях закладки «Розпізнати» може бути мало. Крім цього, ще потрібно на етапі розмітки правильно позначити ці області маркером «Призначення тексту» з контекстного меню.
Вичитка
Вичитування розпізнаного тексту у FineReader можна робити двома способами. Або за допомогою функції "Перевірка", або звичайним чином, переглядаючи сторінки у вбудованому редакторі FineReader. Через вікно «Великий план» звіряємо зі сканом, де є помилки – виправляємо.
Функція «Перевірка» запускається кнопкою у верхньому правому куті меню або через Ctrl-F7. Її робота побудована на тому, що під час розпізнавання FineReader позначає символи та слова, які були розпізнані із недостатньо високим рівнем достовірності. Тобто програма з їх приводу має певний сумнів «може це дійсно той символ, який вам пред'явлений, але може бути і щось інше». Під час перевірки такі сумнівні місця по черзі показуються користувачеві, щоб він у разі потреби їх поправив.
Вікно перевірки влаштоване досить легко. У верхній його частині показується фрагмент сторінки, в якому знаходиться символ, що перевіряється. У нижній частині відображається рядок розпізнаного тексту з цим символом, а також розташовані кілька кнопок для нескладного редагування.

Мал. 23. Вікно «Перевірка»
Якщо все гаразд, символ визначено правильно, то натискаємо на «Пропустити». Якщо він визначений неправильно, то вводимо правильне значення або за допомогою клавіатури, або якщо на клавіатурі такого немає, за допомогою кнопки «Вставити символ» (грецька літера «омега»). Після чого натискаємо на «Підтвердити».
Аналогічно діємо якщо символ розпізнаний правильно, тоді як його форматування - неправильно. Наприклад у тексті книжки десь йде курсив, а розпізнався він, як звичайний шрифт. Для переформатування використовуємо кнопки у нижній частині вікна.
Але можливості вікна перевірки все ж таки досить обмежені. І по тому, якого розміру шматочок сторінки може бути показаний у верхній частині вікна, і за можливостями редагування, які є. Тому всі переміщення текстом, від однієї точки перевірки до іншої, відстежуються ще й у вікнах «Текст» і «Великий план». Увесь час, поки триває робота, курсори в «Тексті» та «Великому плані» переміщуються синхронно їх становищу у «Перевірці».
Якщо в фрагменті сторінки, що перевіряється (в його скані) раптом потрібно було побачити більше, ніж кілька слів, показаних у «Перевірці», то можна це зробити в «Великому плані». Якщо для виправлення поточної помилки потрібні можливості редактора з «Тексту», то можна на якийсь час переключитися в нього (просто клацнувши на його віконце), зробити необхідну роботу і повернутися назад в «Перевірку» (клацнувши на її віконце). Після повернення до «Перевірки» там будуть відображені всі зміни, які ви зробили в «Тексті».

Мал. 24. Приклад роботи у одночасно відкритих вікнах «Перевірка», «Текст» та «Великий план»
Якщо вам віконце «Перевірка» з його обмеженими можливостями не дуже зручно (звикли працювати з усіма зручностями текстових редакторів і звички міняти не збираєтеся), то можна з самого початку виконувати цю роботу у вікні «Текст».
Місця, що вимагають перевірки, там відображаються в повному обсязі – це символи та слова, виділені світло-блакитним. Можливість переміщатися від помилки до помилки, не переглядаючи всю сторінку, теж є - кнопки «Наступна помилка» та «Попередня помилка» на панелі кнопок з лівого боку вікна.
Теоретично, за задумом творців FineReader, вікна «Перевірка» має бути цілком достатньо для повноцінного вичитування розпізнаного тексту. Всі сумнівні місця зазначені, рухаємося вздовж них, керуємося помилками, на виході отримуємо повністю очищений текст.
Але, як це часто буває, теорія тут розходиться із повсякденною практикою роботи. У розпізнаних текстах систематично зустрічаються помилкові місця, які, як помилки, не позначені. Тобто FineReader розпізнає якийсь символ/слово невірно, але з упевненістю, що розпізнав правильно.
Тому для повноцінної вичитки одного вікна «Перевірка» зазвичай буває недостатньо - особливо якщо в тексті багато наукових чи технічних термінів, професійного жаргону тощо «несловенності». Треба ще пройтися по розпізнаному вручну - уважно переглянути його у вікні «Текст» і перевірити всі більш-менш сумнівні місця.
Вичитування тексту у вікні «Текст» мало чим відрізняється від звичайної коректорської роботи. Налаштовуєте вікна «Текст» і «Великий план» так, щоб вони займали більшу частину робочого вікна програми, переходьте до чергової сторінки, що перевіряється, переглядаєте її текст. Якщо виявляєте сумнівне чи явно помилкове місце, то клацаєте по ньому - при цьому курсор у «Великому плані» встановлюється точно в тому самому місці оригіналу (скана). Порівнюєте оригінал і розпізнане, за потреби правите, рухаєтеся далі.

Мал. 25. Вичитування за допомогою вікон «Текст» та «Великий план»
Функціональність редактора вікна "Текст" нічим особливо не відрізняється від функціональності будь-якого текстового редактора середнього ступеня складності. Вигляд у кнопок у меню досить типовий, будь-яких проблем при роботі з ними виникати не повинно. Якщо треба поправити якийсь символ, який на клавіатурі відсутній, то, як і в віконці «Перевірка», треба натиснути на кнопку з грецькою «омегою» і в таблиці, що відкрилася, вибрати необхідне.
Збереження результатів
Коли відсканований матеріал розпізнаний і вичитаний, його треба зберегти в одному з документальних форматів - DOC, DOCX, RTF, PDF, HTML і т.д. в основному меню FineReader.
У вікні Провідника, що відкрилося, вибираєте формат, через кнопку «Налаштування» задаєте параметри збереження, натискаєте «ОК». Якщо хочете відразу ж подивитися чи немає помітних помилок у зовнішньому вигляді збереженого тексту, то окрім цього поставте галочку «Відкрити документ після збереження». Тоді він одразу ж буде відкритий у редакторі (браузері, програмі перегляду).

Мал. 26. Вікно збереження розпізнаного тексту
Звичайна практика розпізнавання - на вхід надходить відсканований текст книги або журналу, на виході всі його сторінки зберігаються у файл під назвою цієї книги. Саме таке налаштування "Створювати один файл для всіх сторінок" стоїть за замовчуванням у рядку "Опції файлу". Якщо ж у вас розпізнається не якийсь цілісний текст, а просто розсип сторінок (наприклад, офісна документація), то тут треба буде виставити «Зберігати окремий файл для кожної сторінки».
Налаштування збереження у форматах DOC, DOCX, RTF

Мал. 27. Налаштування збереження в DOC/DOCX/RTF
Ключове і основне, що тут треба вибрати - це з яким ступенем точності в документі, що зберігається, буде відображено зовнішній вигляд оригіналу (один з режимів збереження в віконці «Оформлення документа»). Всі інші налаштування – не більше, ніж уточнення та деталізація цього пункту.
Варіантів вибору тут чотири: «точна копія», «редагована копія», «форматований текст» та «простий текст».
1. "Точна копія".
За задумом розробників тут мала бути практично дзеркальна подоба сторінки, що розпізнається. Саме тому так і названо. З точним відтворенням шрифтів, розмірів літер (кеглів), відстаней між літерами в словах, відстаней між словами, рядками та абзацами та інших деталей верстки. Ідея загалом непогана, але можливості реалізувати її в задуманому обсязі у FineReader зазвичай не вистачає.
Шрифти та його зображення (Normal, Italic, Bold) часто відтворюються за принципом «як вийде, і вийде». Можуть бути передані точно. Може статися так, що шрифт, використаний на сторінці, що розпізнається, буде заміщений іншим шрифтом (подібним по вигляду, але іншим). Може статися так, що зображення Normal буде розпізнане як Bold або навпаки. І так далі і тому подібне.
З відтворення кеглів, відстаней та іншого форматування ситуація не набагато краща - більш-менш точно відтворити зовнішній вигляд (верстку) сторінки, що розпізнається, зазвичай вдається лише у випадках чогось не дуже складного.
В результаті виходить не дуже зрозуміло, що - Word-документ, який можна тільки читати (та й копіювати звідти текст). Редагувати його за межами "пару букв прибрати, пару букв вставити" малореально. А редагувати таки потрібно - адже він далі піде в якусь роботу, а отже треба буде переробляти форматування під потреби майбутнього використання.
З одного боку, весь текст тут розкиданий по численних кадрах, що неабияк ускладнює роботу з ним. З іншого боку, під час розпізнавання програма генерує купу Word'івських стилів - все форматування в тексті робиться виключно через стилі. Звичайно, коли на текст книги середнього розміру (300-400 сторінок) генерується кілька сотень різних стилів. Що ще більше ускладнює редагування.
Резюме - вибирати цей режим збереження особливого сенсу немає, працювати зі збереженим текстом тут досить незручно.
Якщо вам потрібно повне відтворення зовнішнього вигляду оригіналу, то це і простіше, і практичніше зробити у вигляді PDF «Текст під зображенням сторінки» або PDF «Тільки текст і картинки» (про ці способи виведення трохи нижче).
2. «Редагована копія».
За змістом це полегшена версія "Докладної копії". Зовнішній вигляд оригіналу відтворюється не з таким ступенем прискіпливості, як у попередньому випадку, фреймів з текстом помітно менше (хоча періодично трапляються). Однак, хоч цей варіант і називається «редагованим», працювати з ним теж, не сказати, щоб зручно.
Якщо Word-документ потрібен, як є, тільки для перегляду його вмісту та скопіювати потрібний фрагмент тексту, то цілком можна використовувати і цей варіант. Якщо потрібно багато переробляти, переформатувати і так далі, то краще вибирати щось інше.
Причина та сама - занадто багато метушні щодо перетворення тексту з того виду, який видасть «Редагована копія», у той вид, який може знадобитися вам. Все ще залишилася якась кількість тексту у кадрах, у форматуванні все ще зберігається тенденція точно відтворювати зовнішній вигляд (верстку) оригіналу. Та й звичка генерувати купу стилів нікуди не поділася.
Резюме – працювати з текстом тут не так клопітно, як у «Точній копії», але, як і раніше, залишає бажати кращого.
3. "Форматований текст".
Ступінь відповідності оригіналу тут зведена до мінімуму – відтворення шрифтів та кеглів, приблизного розташування матеріалу на сторінках оригіналу, загального виду тексту та таблиць.
Працювати з цим варіантом помітно простіше, ніж із попередніми, проте все ще важко через велику кількість стилів. Втім, це досить просто лікується - можна швидко пройтися по тексту і накласти на нього ваш власний комплект стилів.
4. "Простий текст".
Хоча він називається "Простий текст", але тут можна зберігати як сам текст, так і текст з картинками. Форматування в цьому варіанті зведено до мінімуму – звичайні Word'івські абзаци від одного краю сторінки до іншого, плюс устромлені між ними картинки. Звична за попередніми варіантами купа стилів також не генерується.
Але за бажання навіть тут можна залишити вихідну розбивку на рядки та на сторінки. Плюс зберігати зображення шрифту - звичайний, курсив, напівжирний.
Зазвичай для збереження вибирається або "Форматований текст", або "Простий текст" - залежно від того, що ви збираєтеся робити далі і використовувати розпізнане.
Тепер про інші налаштування цього вікна.
- "Розмір паперу за замовчуванням".
Тут задається Word'івське налаштування «Параметри сторінки → Розмір паперу», тобто на папері якого формату ви робитимете роздруківку. Зазвичай виставляється А4. Але треба мати на увазі, що в режимах «точна копія» і «редагована копія» один до одного зберігається не тільки вміст розпізнаної сторінки, але і її вихідний розмір. У результаті якщо поставити тут формат паперу, більший за розмір сторінки, то при друкуванні навколо тексту будуть порожні поля. Якщо поставити менший формат, то частина матеріалу сторінки може бути втрачена (виявиться за межами аркуша паперу). - «Зберігати перенесення та поділ на рядки».
Якщо галочка поставлена, буде збережено та розбивка на рядки, яка є в оригіналі. Перенесення рядків у цьому випадку робляться м'якими. Якщо галочки не ставити, текст піде звичайними Word-івськими абзацами, з рядками від одного краю сторінки до іншого. - "Зберігати поділ на сторінки".
Якщо галочка поставлена, то буде збережено розбивку на сторінки, яка є в оригіналі. Якщо галочки не ставити, то текст на сторінки розбиватиме сам Word. - «Зберігати колонтитули та номери сторінок».
Якщо галочка поставлена, то текст, розмічений і розпізнаний, як колонтитули та номери сторінок, буде збережено та розміщено у відповідних Word-івських полях. Якщо галочку не ставити, ця частина тексту взагалі не виводиться. - "Зберігати номери рядків".
Якщо галочка поставлена, то у списках із пронумерованими рядками буде збережено нумерацію цих рядків. - "Зберігати колір фону та літер".
Якщо поставлена галочка, то текст, надрукований у кольорі (або на кольоровому тлі), буде виведений, як в оригіналі. Якщо галочки не ставити, весь текст буде виводитися звичайним чином - чорним на білому тлі (або на білому на чорному тлі). - «Зберігати напівжирний шрифт, курсив та підкреслення у простому тексті».
Висновок в «Простий текст» можна робити за принципом «все одним і тим самим зображенням, Normal», а можна зі збереженням зображення, яке було в оригіналі. Тут саме цей момент і регулюється. - "Виділяти невпевнено розпізнані символи".
Цю галочку треба ставити, якщо ви волієте вичитувати розпізнаний текст не в FineReader, а в якомусь текстовому редакторі. Тоді всі позначки символів та слів, які у вас були у вікні «Текст», будуть відтворені у збереженому документі. - "Зберігати картинки".
Чи буде окрім тексту зберігатися ще й зображення. - "Якість картинок".
Тут визначається ступінь стиснення зображень із оригіналу. Воно може регулюватися за трьома напрямками - через різні алгоритми стиснення, через дозвіл зображення і через глибину кольору в ньому. Подробиці можна переглянути, якщо у рядку «Якість картинок» вибрати варіант «Користувачське». Найбільш практично користуватися саме ним, а не пресетами «Невеликий розмір (150 dpi)» та «Висока якість (дозвіл вихідного зображення)».
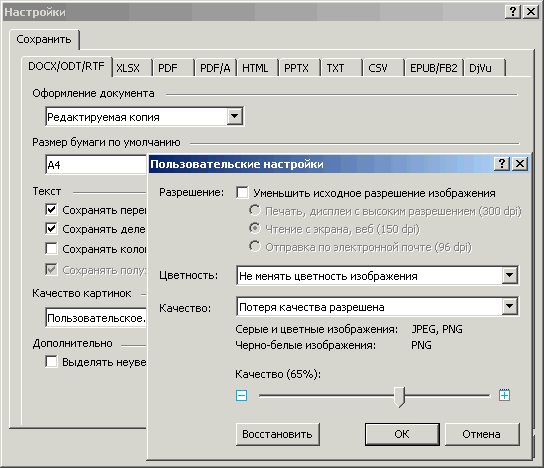
Мал. 28. Вікно налаштування якості зображення
Оскільки при зменшенні вихідної роздільної здатності та подальшому стисканні можливі погано передбачувані спотворення, то галочку «Зменшувати вихідну роздільну здатність зображення» краще прибрати.
Глибину кольору ставите за ситуацією. Якщо зображення потрібні, як є, вибираєте «Не змінювати кольоровість зображення». Якщо досить просто загального вигляду, точне відтворення кольорів не обов'язково, вибираєте «Конвертувати кольорові зображення в сірі». Перетворення кольорових і сірих зображень у чорно-білі краще не вибирати, тому що бінаризація може давати багато спотворень (причому погано передбачуваних). Пункт «Автоматично» теж краще не вибирати – не дуже зрозуміло, яка логіка роботи там закладена і що ви при цьому отримуватимете на виході.
Налаштування збереження у форматах PDF та PDF/A

Мал. 29. Налаштування збереження у PDF
Режимів збереження тут також чотири: "Тільки текст і картинки", "Текст поверх зображення сторінки", "Текст під зображенням сторінки", "Тільки зображення".
- "Тільки текст і картинки".
Тут ви фактично отримаєте PDF-варіант того, що видається у «Точній копії» - розпізнаний текст та ілюстрації з вікна «Текст» у вигляді максимально наближеному до оригіналу. Якість відтворення оригіналу тут вища, ніж у DOC/DOCX/RTF, оскільки PDF-формат має для цього помітно більше можливостей. - "Текст поверх зображення сторінки".
Це PDF, що складається з двох шарів – вихідне зображення (нижній шар), на яке накладено розпізнаний текст (верхній шар). Такий варіант досить зручний, якщо PDF потім редагуватиметься - "Текст під зображенням сторінки".
Цей PDF складається з двох шарів - вихідне зображення і розпізнаний текст. Тільки вони йдуть у зворотному порядку – зображення верхнім шаром, текст нижнім (невидимим) шаром. Такий спосіб виводу ще називається "PDF з текстовою підкладкою" і використовується, коли треба отримати з одного боку точну копію зовнішнього вигляду оригіналу, а з іншого боку, можливість копіювати текст цього оригіналу. - "Тільки зображення".
Це PDF, зібраний із вихідних зображень. Крім самих зображень, там більше нічого немає.
Тепер про інші налаштування цього віконця.
1. "Розмір паперу за замовчуванням".
У PDF-виводі зміст цього налаштування такий самий, як і в попередньому випадку - формат аркуша, на якому друкуватиметься сторінка.
У попередньому випадку йшлося про правило «якщо сторінка менша за заданий формат, то навколо тексту будуть порожні поля, якщо більше - частина тексту буде обрізана». У PDF воно дотримується ще жорсткіше, оскільки тут вихідна сторінка у будь-якому варіанті відтворюється один до одного. Тому найрозумніше ставити тут «Використовувати розмір оригіналу».
2. «Зберігати колір фону та літер».
3. "Зберігати колонтитули".
Сенс цих двох налаштувань такий самий, як і в попередньому випадку.
4. «Створити зміст».
Якщо в налаштуваннях розпізнавання була поставлена галочка «Визначення структурних елементів → Зміст», розпізнаний таким чином вміст книги може бути використаний для автоматичного створення змісту у PDF-файлі.
5. «Дозволити PDF-теги».
У PDF теги - це функціональний аналог Word-вських стилів, спосіб структурної розмітки вмісту PDF-файлу. З їх допомогою зберігається інформація про розбивку тексту на розділи, про заголовки, зміст, ілюстрації, таблиці, примітки, гіперпосилання, математичні формули тощо.
Якщо вам потрібно часто копіювати з PDF шматки тексту, то галочку тут варто поставити. Тоді скопійований текст буде більше відповідати тому, як він виглядає на сторінці PDF.
Також теги корисні, якщо PDF доводиться переглядати на екранах різних розмірів - від десктопів до смартфонів. У таких випадках PDF-читалкам доводиться переформатувати вміст сторінок під поточний розмір екрана і з теговою розміткою це проходить значно акуратніше, без помітних спотворень початкового вигляду.
6. "Використовувати змішаний растровий вміст (MRC)".
MRC (Mixed Raster Content) - це назва технології стиснення, здатної давати помітно більші кратності стиснення, ніж відомі всім JPEG і JPEG 2000. Багато хто знайомий з нею за форматом DjVu - він побудований саме на базі MRC. Вибір «треба ставити галочку чи ні» тут неоднозначний і визначається, виходячи з вашого розкладу справ.
Основний плюс - розмір PDF. Може бути в кілька разів менше PDF, отриманого з тими самими параметрами стиснення, але без MRC.
Які можуть бути мінуси:
MRC-стиск так влаштовано, що при роботі завжди дає погано передбачувану кількість спотворень. Через те, що спотворення тут лише частиною залежать від налаштувань стиснення, а в значній мірі від вмісту сторінки. Текст, малюнки, графіки, фотографії - при MRC-стиску всі вони поводяться помітно по-різному і дають різну кількість спотворень.
Помітно велика ресурсомісткість при стисканні та перегляді таких PDF. Навіть на сьогоднішніх комп'ютерах MRC-PDF може відкриватися і перегортатися не звично-плавно, а стрибками, коли чергова сторінка виводиться на екран не вся відразу, а частинами.
7. "Зберігати картинки".
8. "Якість зображення".
Сенс цих налаштувань такий самий, як і в попередньому випадку - треба чи не треба при створенні PDF зберігати зображення та з яким рівнем стиснення їх зберігати. Рекомендації теж аналогічні - прибрати галочку з «Зменшити вихідну роздільну здатність», кольоровість краще не змінювати, двигун «Якість» виставляти за аналогією зі стисненням у JPEG 2000.
9. "Шрифти".
Якщо поставити «Використовувати шрифти Windows», то для розпізнавання та подальшого виводу буде використовуватися той набір шрифтів, який встановлено на комп'ютері. Якщо поставити «Використовувати наперед визначені шрифти», то тільки той комплект шрифтів, який встановлюється при інсталяції FineReader.
Краще виставляти перший варіант, оскільки при цьому буде використовуватися набагато більша різноманітність шрифтів і програмі буде легше підбирати відповідність шрифтам книг, що розпізнаються.
10. "Вбудовувати шрифти".
Якщо вам потрібно, щоб під час перегляду PDF-файлу на іншому комп'ютері він був видно саме так, як ви його отримали (саме у цих шрифтах), то треба поставити тут галочку.
11. "Параметри захисту PDF".
Тут можна виставити парольний захист на перегляд PDF, друк, копіювання тексту та малюнків, редагування.
Якщо у вас виникнуть питання щодо роботи FineReader, на які ви не знайшли відповіді в тексті статті, їх можна задати розробників програми.
Історія Abbyy FineReader налічує вже понад 20 років. Ювілейний 2013 р. компанія відзначила випуском повноважного (порівняно з Express Edition від 2009 р.) Abbyy FineReader Pro для Mac, а через пару місяців, у лютому 2014 р., свій «подарунок» отримали і користувачі Windows – Abbyy FineReader 12 Professional та Corporate. Нагадаю, що попередня версія з'явилася ще в 2011 р., а два з половиною роки термін немалий - давайте розбиратися, наскільки суттєвими є зміни.
Загальна інформація
Системні вимоги для нової версії не змінилися. Платформою може служити Windows або Windows Server, починаючи від XP і 2003 відповідно. Апаратні запити по теперішніх часах і погано скромні: процесор будь-якої розрядності з частотою від 1 ГГц, оперативної пам'яті не менше 1 ГБ плюс по 512 МБ на кожне обчислювальне ядро і т. п. Дещо збільшилася тільки потреба в дисковому просторі - тепер для встановлення потрібно 700, а 850 МБ (плюс, як і раніше, ще 700 МБ для робочих файлів).
Звичайно, йдеться про мінімальні вимоги; Можливості Abbyy FineReader 12 Professional розкриються тільки на порівняно сучасних системах. Зокрема, нагадаю, що програма вміє ефективно розпаралелювати обробку окремих сторінок, задіяє при цьому всі процесорні ядра та завантажує будь-який процесор майже на 100%. А ось до оперативної пам'яті вона справді не жадібна, і навіть залишається 32-розрядною.
Не зазнала змін і процедура встановлення: мінімум питань та опцій. У комплекті з Abbyy FineReader 12 Professional, як і раніше, йде Abbyy Screenshot Reader, який стає працездатним тільки після реєстрації користувача.

Після цього також відкриється доступ до техпідтримки.

Навіть на основі цієї скромної інформації можна припустити, що маємо результат еволюції. Відповідно, надалі я зосереджуся на описі змін у порівнянні з попередньою версією, які умовно можна розділити на дві основні групи: робота з програмою (інтерфейс, допоміжні інструменти, зручність використання) та OCR (якість та продуктивність власне розпізнавання).
Робота з програмою
Abbyy FineReader 12 Professional демонструє деякі доробки в частині інтерфейсу користувача. Це відразу помітно на вікні Завдання, яке за замовчуванням відкривається під час запуску програми. Воно, очевидно, імітує концепцію плиток Windows 8.x і адаптоване для керування пальцями, тим більше, що в програмі також підтримуються основні жести на кшталт прокручування і масштабування. Насправді ж, зміни торкнулися лише «фасаду», та й то частково – поруч із плитками є сусідами звичайні елементи управління і в процесі налаштування будь-якого сценарію доведеться мати справу зі стандартними діалоговими вікнами. Працювати з ними пальцями досить проблематично, особливо на екранах 8-10″, які набувають популярності у Windows-планшетів.

Уявити, що користувач такого планшета, оснащеного камерою, може захотіти швидко «на ходу» ввести якийсь друкований документ, дійсно нескладно. Тим часом, вся історія Windows, починаючи з першої редакції Tablet PC, підтверджує безглуздість адаптації до сенсорного управління стандартного настільного інтерфейсу. Очевидно, цих цілей набагато правильніше створювати спеціальну оболонку, відповідну всім канонам Metro, але використовує той самий «движок». Прикладом такого рішення є Internet Explorer з Windows 8.x. До того ж, у Abbyy навіть є якийсь доробок у вигляді Abbyy FineReader Touch для Windows 8, який використовує хмарний сервіс компанії.
Якщо ж відволіктися від сенсорного введення, то знайдуться ще зміни даного класу - від очікуваного оновлення вікон відкриття/збереження документів, які, серед іншого, забезпечують простий доступ до хмарних сховищ (за наявності в системі відповідного агента та його папки), до кількох більше важливих та корисних.

Обробка сторінок в Abbyy FineReader 12 Professional тепер виконується у фоновому режимі. Це має на увазі відсутність колишнього модального вікна зі статусом операцій (тепер цю роль відіграє рядок статусу внизу екрана) і, відповідно, наявність доступу до інтерфейсу. Таким чином користувач має можливість працювати з програмою паралельно до процесу розпізнавання (якщо він, звичайно досить тривалий), наприклад, копіювати фрагменти отриманого тексту або навіть коригувати розмітку сторінок - останні при цьому будуть поставлені в чергу і оброблені заново.

На відміну від попередньої версії, також не відбувається перегортання сторінок у міру розпізнавання або при початковому завантаженні документа, якщо автоматичне розпізнавання вимкнено. В Abbyy FineReader 12 Professional документ завантажується та розбивається на сторінки практично миттєво, а їх ескізи будуються лише у міру ручного перегортання у лівій панелі. Крім усього іншого, тим самим економляться обчислювальні ресурси, причому досить відчутно на великих багатосторінкових документах.
Інші зміни даного класу не такі цікаві, хоча і можуть стати в нагоді в якихось сценаріях, тому про них коротко.
Якщо потрібно не обробити документ повністю, а лише процитувати окремі місця, то можна відключити всі автоматичні операції та вибирати необхідні фрагменти будь-яких типів, відразу ж копіюючи їх у буфер обміну - при цьому аналіз та розпізнавання виконуватимуться на льоту.


Для отримання результату з більш простою структурою, ніж у оригіналу, можна відключати відтворення колонтитулів, виносок та інших елементів макету. Це може стати в нагоді, наприклад, під час підготовки електронних книг.

Продовжуючи електронні книги - в Abbyy FineReader 12 Professional підтримуються формати EPUB 2.0.1 і 3.0.

Розширені параметри перетворення XLSX, наприклад, з'явилася можливість очищати форматування чи зберігати картинки.

При збереженні результуючих документів у PDF з текстовим шаром можна скористатися новою технологією Abbyy Precise Scan, яка полягає в згладжуванні символів на оригінальних зображеннях сторінок. Доступна вона, до речі, лише у кольоровому режимі.

Ефект від її роботи досить помітний, хоч і не завжди, скажімо так, «академічний». Втім, читабельність згладжених символів у будь-якому випадку має бути вищою, а в даному прикладі оригінал справді дуже низької якості.


OCR
Тепер давайте розберемося, які покращення відбулися у механізмах власне розпізнавання.
Розробники повідомляють про черговий етап удосконалення технології ADRT, яка, нагадаю, аналізує та відтворює логічну структуру документа. Декларується, що вона почала працювати набагато точніше, особливо з таблицями, списками, діаграмами. Продемонструвати це адекватними прикладами непросто, але неможливо. Ось, наприклад, результати розпізнавання (з налаштуваннями за замовчуванням) однієї й тієї ж сторінки Abbyy FineReader 11 Professional (вгорі) і Abbyy FineReader 12 Professional (внизу).


Стара версія виділила і обробила тільки основний текстовий блок, можливо, через низьку якість оригіналу вважаючи інші елементи «сміттям». Нова, навпаки, коректно впізнала список та спробувала його відтворити. Результат, щоправда, не ідеальний: те, що розпізнані не всі маркери можна, знову ж таки, віднести на якість зображення, але програма, мабуть, все ж таки не зрозуміла, що перед нею зміст, інакше не інтерпретувала б цифри як літери. Проте прогрес очевидний і на якісніших оригіналах подібних претензій, можливо, не було б.
А ось як обробляється «неявна» таблиця без розділових ліній – Abbyy FineReader 11 Professional (угорі) та Abbyy FineReader 12 Professional (внизу).


Добре видно, що стара версія, на відміну нової, взагалі побачила тут табличної структури і обмежилася набором незв'язаних між собою текстових блоків. Не полінуйтеся клацнути на зображеннях та порівняти результати розпізнавання – у Abbyy FineReader 12 Professional він близький до ідеалу.
На жаль, так відбувається не завжди і вже на сусідніх сторінках Abbyy FineReader 12 Professional показав результати, аналогічні до Abbyy FineReader 11 Professional. Хоча саме ADRT мала б відстежити однакові «шапки» і зрозуміти, що перед нею своєрідна перетікаюча таблиця.

Але все одно добре помітно, що оновлені алгоритми звертають увагу на більшу кількість деталей, ніж раніше. У процесі тестування Abbyy FineReader 12 Professional спостерігалася, наприклад, навіть спроба інтерпретувати як таблицю картинку з упорядкованим розміщенням у ньому текстової інформації. Набагато частіше також нова версія намагається відтворювати різні діаграми та схеми на основі фонового малюнка, а не з окремих графічних та текстових блоків.
Є ще кілька новинок, покликаних підвищити якість розпізнавання в Abbyy FineReader 12 Professional. Як відомо, однією з передумов для цього є якість оригіналу, особливо якщо його отримано за допомогою не сканера, а фотокамери. Саме тому свого часу у FineReader з'явилися засоби попередньої обробки оригіналів. У новій версії їх список розширено, додалися обрізка по краях сторінок, освітлення та вирівнювання яскравості фону, видалення кольорових елементів. Останнє може стати в нагоді, наприклад, для обробки документів з печатками та штампами. Крім того, користувач може підключати різні методи індивідуально.

Поліпшено також мовну підтримку. По-перше, з'явився російський алфавіт з наголосами, по-друге, декларується підвищення якості розпізнавання китайської, японської та корейської (до 20%), арабської (до 60%), івриту (до 10%) – досягнуто це, мабуть, за рахунок вдосконалення та додаткового тренування класифікаторів.

Ну і нарешті, одне з найбільш актуальних питань для багатьох читачів: чи зросла швидкість роботи програми? Аргументовано відповісти на це питання, тим більше з цифрами, не так просто - занадто багато мов, кожна з яких має свої нюанси; занадто велика різноманітність оригіналів; надто багато невідомих нам факторів впливу на роботу алгоритмів. Тому навіть розробники досить стримано говорять про зростання продуктивності Abbyy FineReader 12 Professional на 10-15%.
Подібні цифри зазвичай виходять за результатами обробки досить великих масивів документів і, відповідно, є чимось на кшталт «середньої температури по лікарні». Тому корисно докладніше вивчити якісь показові окремі випадки, наприклад, подібні до двох наступних:
- відскановані у кольорі з роздільною здатністю 300 dpi 10 сторінок повнокольорового буклету формату A4. Якість хороша, мови російська та англійська, макет складний;
- PDF із графічними зображеннями 138 сторінок книги, що містить невелику кількість кольорових та чорно-білих ілюстрацій, кілька таблиць. Якість низька (починаючи, мабуть, зі «сліпого» друку у паперовій книзі), мови українська та російська, макет простий.
Обидва документи розпізнавались у кольоровому режимі, а другий також у чорно-білому, що мало на меті імітувати процес підготовки електронної книги. За замовчуванням всі налаштування залишалися без змін, за винятком набору мов і, відповідно, режимів роботи. Як тестовий полігон використовувався ПК з процесором i5-3450 і 8 ГБ пам'яті. Результати представлені у наступній таблиці:
Як видно, для PDF прискорення навіть перевищує обіцяні 15% - можливо, це якраз один із особливих випадків, які добре підходять для останніх оптимізації в алгоритмах розпізнавання. При цьому треба мати на увазі, що програми, взагалі кажучи, зробили різний обсяг роботи. Погляньте хоча б на ілюстрації вище до обробки таблиць - важко сказати, яка з версій довелося складніше.
Щодо кількості помилок, то вона в обох версій практично збігалася, хоча було помітно, що іноді сумніви викликають різні фрагменти та символи – це, мабуть, є свідченням тренування алгоритмів. У будь-якому випадку, більшість невпевнено розпізнаних символів абсолютно коректно ідентифікувалося за допомогою словників, а «грубі» помилки (некоректна інтерпретація спеціальних та декоративних символів, тексту на графіці тощо) збігалися. Так що різницю взагалі можна вважати зникаючою.
Інше питання, наскільки подібне підвищення продуктивності взагалі має значення? Очевидно, виграш за півхвилини на 138 сторінках, які все одно потрібно перевіряти і, можливо, коригувати, трохи коштує. Якщо роботи, подібні до тестових завдань, передбачається виконувати час від часу, то про продуктивність можна точно не переживати. Інша річ, якщо йдеться про автономну обробку великих обсягів документів, яка доступна в Abbyy FineReader 12 Corporate. У такому разі економія 15% часу вже цілком відчутна.
Резюме
Незважаючи на те, що новий Abbyy FineReader 12 Professional не обіцяв нічого революційного, принаймні кілька змін у ньому заслуговують на всіляку похвалу. Насамперед, це удосконалення технології ADRT у частині розпізнавання таблиць, діаграм та взагалі логічної структури сторінок, що в деяких випадках дозволяє отримувати кардинально кращі результати, а також фоновий режим обробки, який відкриває нові можливості для інтерактивної роботи з великими документами.
Інших змін також чимало, хоча вони менш значущі. Рух у бік підтримки сенсорного управління сьогодні безумовно виправданий, проте шлях обраний порочний - забезпечити в одному інтерфейсі однаково зручну роботу мишею та пальцями навряд чи можливо. Втім, поки що Windows-планшети тільки намагаються пробитися на ринок, і у розробників з Abbyy ще є час.
Ціни на Abbyy FineReader 12 Professional:
- коробкова версія: 4990 руб.;
- версія для скачування: 4490 руб.;
- оновлення: 2690 руб.
Як завжди, відповідь на запитання «чи варто змінювати стару версію на нову?» залежить від ситуації. У будь-якому випадку варто враховувати, що життєвий цикл у FineReader досить тривалий, і якщо якесь із описаних поліпшень відіграє вам скільки-небудь істотну роль, то за 2-3 роки витрати на оновлення напевно окупляться - якщо не матеріально, то морально. Вирішити для себе це питання остаточно допоможе.
Переклад тексту в цифровий формат – досить поширене завдання для тих, хто працює з документами. Програма Abbyy Finereader допоможе зберегти чимало часу, автоматично переводячи написи з растрових картинок або «читалок» в текст, що редагується.
У статті розглянемо, як використовувати Abbyy Finereader для розпізнавання текстів.
Як розпізнати текст із картинки за допомогою Abbyy Finereader
Щоб розпізнати текст на растровому зображенні, досить просто завантажити його в програму, і Abbyy Finereader автоматично розпізнає текст. Вам залишається лише редагувати його, виділивши потрібне та зберегти у потрібному форматі або скопіювати в текстовий редактор.
Розпізнати текст можна прямо із підключеного сканера.
Докладніше читайте на нашому сайті.
Як створити PDF та FB2 за допомогою Abbyy Finereader
Програма Abbyy Finereader дозволяє конвертувати зображення у універсальний формат PDF та формат FB2 для читання на електронних книгах та планшетах.
Процес створення таких документів схожий.
1. У головному меню програми виберіть E-Book і натисніть FB2. Виберіть тип вихідного документа — сканування, документ або фотографію.

2. Знайдіть та відкрийте потрібний документ. Він завантажиться в програму посторінково (це може тривати деякий час).
3. Коли процес розпізнавання завершиться, програма запропонує вибрати формат збереження. Вибираємо FB2. За потреби заходимо в «Опції» та вводимо додаткову інформацію (автор, назва, ключові слова, опис).

Після збереження можна залишитися в режимі редагування тексту та перевести його у формат Word або PDF.
Особливості редагування тексту в Abbyy Finereader
Для тексту, який розпізнав Abbyy Finereader, передбачено кілька опцій.
У вихідному документі збережіть картинки та колонтитули, щоб вони перенеслися до нового документа.

Проведіть аналіз документа, щоб знати, які помилки та проблеми можуть виникнути в процесі перетворення.

Редагуйте зображення сторінки. Доступні опції кадрування, фотокорекції, зміни роздільної здатності.

Ось ми і розповіли як користуватись Abbyy Finereader. Він має досить широкі можливості редагування та конвертування текстів. Нехай ця програма допоможе створити будь-які потрібні вам документи.